
반응형
Notice
Recent Posts
Recent Comments
Link
개발은 처음이라 개발새발
[selenium] 셀레니움으로 크롤링 해보기 - 네이버 축구 순위 1편 본문
반응형
이제 본격적으로 크롤링을 진행해보겠습니다. 우선 전에 적었던 크롬드라이버를 여는 코드까지는 아래와 같습니다.
from selenium import webdriver
#open webdriver
chrome_driver = './chromedriver.exe'
driver = webdriver.Chrome(chrome_driver)제가 이번에 크롤링 해볼 것은 네이버의 해외축구 팀순위 테이블입니다. 그중에서도 저는 분데스리가의 바이에른 뮌헨 팬이라 분데스리가 팀순위를 크롤링 해 이를 데이터 프레임에 저장해 표출해 보도록 하겠습니다. 이를 위해서는 크롤링을 진행하기 전에 컬럼이 들어가 있는 데이터 프레임을 만들어야 하는데요. 우선 네이버 분데스리가 팀순위 테이를 보시죠.
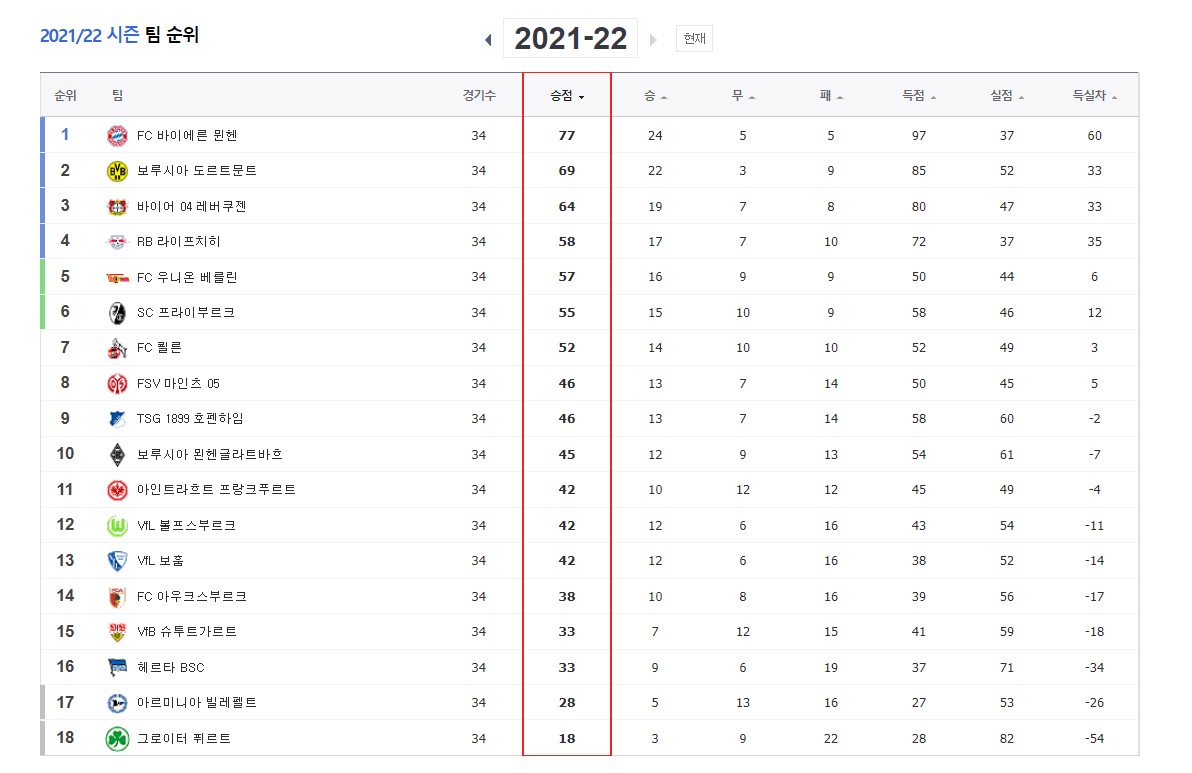
2021/22시즌의 순위 테이블을 보시면 순위, 팀명, 경기수, 승점, 승, 무, 패, 득점, 실점, 득실차 총 10개의 항목이 있습니다. 이 항목들을 컬럼으로 만들어 빈 데이터 프레임을 만들어줘야 합니다. 코드는 아래와 같습니다.
from selenium import webdriver
import pandas as pd
#open webdriver
chrome_driver = './chromedriver.exe'
driver = webdriver.Chrome(chrome_driver)
df_bundes_team = pd.DataFrame(columns = ['rank', 'team', 'game', 'win_pt', 'win', 'draw',
'lose', 'gf', 'ga', 'goal_diff'])빈 데이터프레임을 만들었으니 크롤링할 웹페이지의 링크를 연결해야 겠죠.
bundes_football이라는 변수에 분데스리가 팀순위 링크를 넣고 driver.get() 함수를 이용해 연결시킵니다.
from selenium import webdriver
import pandas as pd
#open webdriver
chrome_driver = './chromedriver.exe'
driver = webdriver.Chrome(chrome_driver)
df_bundes_team = pd.DataFrame(columns = ['rank', 'team', 'game', 'win_pt', 'win', 'draw',
'lose', 'gf', 'ga', 'goal_diff'])
bundes_football = "https://sports.news.naver.com/wfootball/record/index?category=bundesliga&tab=team"
driver.get(bundes_football)
driver.implicitly_wait(3)driver.implicitly_wait(3)은 대기 시간을 3초 준다는 의미입니다. 이렇게 크롤링하고자 하는 링크까지 연결을 완료했습니다. 다음편에서는 어떻게 순위 테이블의 항목들을 긁어오는지와 결과물을 보여드리도록 하겠습니다.
반응형
'파이썬 > 크롤링' 카테고리의 다른 글
| 셀레니움으로 네이버 로그인 1편 (2) | 2022.07.10 |
|---|---|
| [selenium] 셀레니움으로 크롤링 해보기 - 네이버 축구 순위 최종장 (0) | 2022.06.06 |
| [selenium] 셀레니움으로 크롤링 해보기 - 네이버 축구 순위 2편 (1) | 2022.06.06 |
| [selenium] 셀레니움으로 크롤링 해보기 - 크롬 드라이버(Chrome driver) (2) | 2022.06.04 |
'파이썬/크롤링' Related Articles
more



