
목록파이썬/크롤링 (5)
개발은 처음이라 개발새발
 셀레니움으로 네이버 로그인 1편
셀레니움으로 네이버 로그인 1편
저는 종종 취미로 스포츠 데이터를 모으는 것을 합니다. 그럴 때 주로 크롤링을 통해 데이터를 수집하는데요. 대부분의 기록 사이트가 오픈돼 있기 때문에 로그인이 필요하지 않지만 가끔 크롤링할 기록실 링크를 직접 넣어도 반드시 로그인을 수반해야 되는 경우가 있습니다. 그럴 때 어떻게 로그인을 해결하는지 네이버를 예시로 한번 진행해 보도록하겠습니다. *** 셀레니움으로 네이버 축구 순위 크롤링 1편 - https://data-so-hard.tistory.com/9?category=976315 2편 - https://data-so-hard.tistory.com/10?category=976315 3편 - https://data-so-hard.tistory.com/11?category=976315 4편 - http..
 [selenium] 셀레니움으로 크롤링 해보기 - 네이버 축구 순위 최종장
[selenium] 셀레니움으로 크롤링 해보기 - 네이버 축구 순위 최종장
from selenium import webdriver import pandas as pd #open webdriver chrome_driver = './chromedriver.exe' driver = webdriver.Chrome(chrome_driver) df_bundes_team = pd.DataFrame(columns = ['rank', 'team', 'game', 'win_pt', 'win', 'draw', 'lose', 'gf', 'ga', 'goal_diff']) bundes_football = "https://sports.news.naver.com/wfootball/record/index?category=bundesliga&tab=team" driver.get(bundes_football)..
 [selenium] 셀레니움으로 크롤링 해보기 - 네이버 축구 순위 2편
[selenium] 셀레니움으로 크롤링 해보기 - 네이버 축구 순위 2편
지난 글에서 네이버 분데스리가 팀순위 페이지까지 연동하는 것을 해봤는데요. 코드는 아래와 같습니다. from selenium import webdriver import pandas as pd #open webdriver chrome_driver = './chromedriver.exe' driver = webdriver.Chrome(chrome_driver) df_bundes_team = pd.DataFrame(columns = ['rank', 'team', 'game', 'win_pt', 'win', 'draw', 'lose', 'gf', 'ga', 'goal_diff']) bundes_football = "https://sports.news.naver.com/wfootball/record/index?c..
 [selenium] 셀레니움으로 크롤링 해보기 - 네이버 축구 순위 1편
[selenium] 셀레니움으로 크롤링 해보기 - 네이버 축구 순위 1편
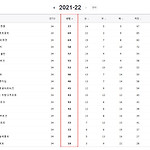
이제 본격적으로 크롤링을 진행해보겠습니다. 우선 전에 적었던 크롬드라이버를 여는 코드까지는 아래와 같습니다. from selenium import webdriver #open webdriver chrome_driver = './chromedriver.exe' driver = webdriver.Chrome(chrome_driver) 제가 이번에 크롤링 해볼 것은 네이버의 해외축구 팀순위 테이블입니다. 그중에서도 저는 분데스리가의 바이에른 뮌헨 팬이라 분데스리가 팀순위를 크롤링 해 이를 데이터 프레임에 저장해 표출해 보도록 하겠습니다. 이를 위해서는 크롤링을 진행하기 전에 컬럼이 들어가 있는 데이터 프레임을 만들어야 하는데요. 우선 네이버 분데스리가 팀순위 테이를 보시죠. 2021/22시즌의 순위 테이블을 ..
 [selenium] 셀레니움으로 크롤링 해보기 - 크롬 드라이버(Chrome driver)
[selenium] 셀레니움으로 크롤링 해보기 - 크롬 드라이버(Chrome driver)
이번에는 크롤링을 해볼까 합니다. 크롤링이라는 단어를 많이 들어봤을테지만 정작 정확한 뜻을 모르는 분도 많을 텐데요. 크롤링이란 간단하게 말하자면 웹페이지에 있는 데이터를 추출해오는 것을 의미합니다. 스포츠 데이터를 예로 들어보면 경기야 얼마든지 볼 수 있지만, 팀과 선수의 기록들을 가지고 재밌게 놀기에는 이와 관련된 회사를 가지 않곤 쉬운 일이 아닌데요. 그러나 크롤링을 할 수 있게 된다면 스포츠 통계 사이트에 있는 데이터를 추출해 저장해서 다양하게 씹고 뜯고 맛보고 즐길 수 있습니다. 그렇다면 지금 바로 크롤링에 대해 알아보도록하겠습니다. 크롤링 라이브러리는 BeautifulSoup4, requests 등 다양하게 있지만 전 selenium을 사용해보려고 합니다. 우선 selenium 라이브러리를 설..