
목록데이터프레임 (11)
개발은 처음이라 개발새발
근래 여러 업무가 겹치면서 포스팅 하는 것도 많이 힘드네요. 업무가 겹치다 보니 포스팅 뿐만 아니라 컬럼명을 외우기도 벅차는데요. 주로 하는 일이 본격적으로 게임을 서비스 하기 위해 데이터 베이스를 구축하기 전 게임에 필요한 스탯의 성장과 인게임 결과에 따른 수치 변동 시뮬레이션을 하는 것이 업이다 보니 긴 컬럼명을 간단하게 변경해 외우기 쉽도록 작업을 하는 경우가 많습니다. 뭐든지 방법에는 처음에 알기 쉽지만 손이 많이 가는 방법 1과 공부를 한다면 몹시도 간단한 방법 2가 존재하는데요. 컬럼명 변경도 마찬가지입니다. 일단 예제를 하나 만들어보겠습니다. import pandas as pd dict_data = {'선수A':[18,3,21,8.13], '김덕배':[3,9,12,7.93], '필포든': [..
https://data-so-hard.tistory.com/50 merge()함수로 데이터프레임 병합하기 [python/pandas] 안녕하세요. 2주만의 포스팅을 하게 됐습니다. 오늘 포스팅할 것은 concat()함수에 이어 merge()함수로 데이터프레임을 병합하는 것입니다. merge()함수는 SQL의 join과 비슷한 방식으로 어떤 기준에 의 data-so-hard.tistory.com 지난 1편에 이어서 merge 함수의 옵션에 대해 알아보겠습니다. 이번 시간에는 'how=' 옵션에 대해 알아보려고 하는데요. how 옵션을 통해서는 왼쪽과 오른쪽을 기준으로 데이터 값을 병합합니다. 또한 left_on과 right_on 옵션을 사용하면 좌우 데이터프레임의 키값을 다르게 지정할 수 있습니다. 우선 ..
안녕하세요. 2주만의 포스팅을 하게 됐습니다. 오늘 포스팅할 것은 concat()함수에 이어 merge()함수로 데이터프레임을 병합하는 것입니다. merge()함수는 SQL의 join과 비슷한 방식으로 어떤 기준에 의해 두 데이터프레임을 병합하는 방법입니다. 이때 기준이 되는 열이나 인덱스를 key라고 부릅니다. 이때 키가 되는 열이나 인덱스는 반드시 합치려는 두 데이터프레임에 모두 존재해야 합니다. 그렇다면 예제를 통해 코딩을 진행해보겠습니다. import pandas as pd df1= pd.read_excel('./stock price.xlsx') df2= pd.read_excel('./stock valuation.xlsx') print(df1) print('\n') print(df2) print(..
하나의 열이 여러가지 정보를 가지고 잇을 때 각 정보를 서로 분리해서 사용하는 경우가 있는데요. 그중에서 대표적인 것이 날짜 정보겠죠. 예를 들어 날짜라는 컬럼 안에 "2022-08-20" 이라는 정보가 담겨 있다면 날짜라는 컬럼에 연도, 월, 일 총 3가지의 정보가 담겨 있는 것입니다. 이름 같은 경우도 성과 이름을 모두 담고 있기 때문에 좀 더 데이터를 세분화해 다루기 위해서는 이를 분리해 구분하는 것이 좋습니다. 이번 시간에는 주가데이터 예제를 통해서 코딩을 진행해보겠습니다. import pandas as pd #데이터셋 가져오기 df = pd.read_excel('./주가데이터.xlsx') print(df.head(),'\n') print(df.dtypes,'\n') #연,월,일 데이터 분리하기 ..
 matplotlib 한글 폰트 오류 해결
matplotlib 한글 폰트 오류 해결
import pandas as pd import matplotlib.pyplot as plt df = pd.read_excel('./시도별 전출입 인구수.xlsx', header=0) #빈칸 채워주기 df = df.fillna(method='ffill') #서울에서 다른 지역으로 이동하는 인구수 mask = (df['전출지별'] == '서울특별시') & (df['전입지별'] != '서울특별시') df_seoul = df[mask] df_seoul = df_seoul.drop(['전출지별'], axis=1) #불필요한 전출지별 제게 df_seoul.rename({'전입지별':'전입지'}, axis=1, inplace=True) #컬럼명 변경 df_seoul.set_index('전입지', inplace=Tr..
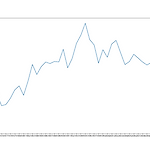 matplotlib로 데이터프레임 그래프 그리기 1
matplotlib로 데이터프레임 그래프 그리기 1
지난 시간에는 df.plot()을 이용해 여러 그래프를 그려봤는데요. 이번 시간에는 또다른 그래프 라이브러리인 maplotlib를 활용해 그래프를 그려보겠습니다. matplotlib는 "파이썬의 표준 시각화 도구"라고 부를 수 있을 정도로 평면 그래프와 관련해 다양한 포맷과 기능을 지원합니다. 또한 객체지향 프로그래밍을 지원해 그래프 요소를 세세하게 꾸밀 수 있는 장점 또한 가지고 있습니다. matplotlib 설명은 여기까지 하고 본격적으로 matplotlib를 이용해 그래프를 그려 보도록하겠습니다. matplotlib를 실행시키기 위해서는 import를 해야 겠죠? 이번에 활용할 데이터프레임은 시도별 전출입 인구수입니다. 코드를 진행해보겠습니다. import pandas as pd import mat..
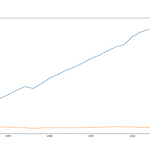 df.plot() 데이터프레임 그래프 그리기 - 2
df.plot() 데이터프레임 그래프 그리기 - 2
지난 1편에서(데이터프레임 그래프 그리기 - 1 https://data-so-hard.tistory.com/17) 그래프는 완성했지만 시각적으로 명확하게 데이터의 차이를 보여줬다고 볼순 없었는데요. 1편에서의 최종 코드와 그래프를 다시 한번 보겠습니다. import pandas as pd import matplotlib.pyplot as plt df = pd.read_excel('./남북한발전전력량.xlsx', engine='openpyxl') # 데이터프레임 변환 print(df) print('\n') df_ns = df.iloc[[0,5], 3:] # 남북한 연도별 발전전량 합계 추출 df_ns.index = ['South', 'North'] # 행 인덱스 변경 print('\n') print(df_..
 df.plot() 데이터프레임 그래프 그리기 - 1
df.plot() 데이터프레임 그래프 그리기 - 1
판다스는 데이터 분석뿐만 아니라 그래프를 통해 데이터의 시각화 역시 가능한 라이브러리인대요. 이번 시간에는 "df.plot()" 을 통해 데이터프레임의 데이터를 시각화 그래프로 표현하는 법을 배우겠습니다. 그렇다면 우선 데이터를 먼저 불러와야 겠죠. 지난 판다스 데이터 분석 자료실을 소개드린 적이 있는데요. 그중 "남북한발전전량.xlsx"을 활용해보겠습니다. 자료실이 궁금하신 분들은 아래의 링크를 통해 확인해주세요. https://data-so-hard.tistory.com/15 파이썬 머신러닝 판다스 데이터 분석 자료실 오늘은 파이썬 교재 중 데이터 분석에 필요한 판다스에 대해 공부할 수 있는 교재와 예제를 다운 받을 수 있는 사이트를 추천드리려고 합니다. 우선 교재는 아래의 링크에 해당하는 교재입니다..
 [selenium] 셀레니움으로 크롤링 해보기 - 네이버 축구 순위 2편
[selenium] 셀레니움으로 크롤링 해보기 - 네이버 축구 순위 2편
지난 글에서 네이버 분데스리가 팀순위 페이지까지 연동하는 것을 해봤는데요. 코드는 아래와 같습니다. from selenium import webdriver import pandas as pd #open webdriver chrome_driver = './chromedriver.exe' driver = webdriver.Chrome(chrome_driver) df_bundes_team = pd.DataFrame(columns = ['rank', 'team', 'game', 'win_pt', 'win', 'draw', 'lose', 'gf', 'ga', 'goal_diff']) bundes_football = "https://sports.news.naver.com/wfootball/record/index?c..
 loc와 iloc (2) - 데이터 변경하기
loc와 iloc (2) - 데이터 변경하기
우선 데이터 프레임을 만듭니다. import pandas as pd exam_data = {'이름': ['민수', '철수', '광수'], '수학': [80, 90, 100], '영어': [95, 88, 56], '국어' : [72, 85, 95]} df = pd.DataFrame(exam_data, index= ['A','B','C']) print(df) 우선 지난 1편에서 한 loc와 iloc를 활용해 특정 범위 데이터 표출 예시를 해보겠습니다. 이와 함께 광수와 철수의 영어 점수를 변경해보겠습니다. #iloc로 특정 데이터 보여주기 label1 = df.iloc[0 : 2] print(label1, '\n') #loc로 특정 데이터 보여주기 label2 = df.loc['A' : 'C'] print(..