
목록판다스 (21)
개발은 처음이라 개발새발
 누락 데이터 치환하기 2 [python/pandas]
누락 데이터 치환하기 2 [python/pandas]
https://data-so-hard.tistory.com/34 누락 데이터 치환하기1 [python/pandas] 이번 시간은 누락 데이터를 제거하는 것이 아니라 치환하는 작업을 진행하겠습니다. 데이터 분석의 품질을 높이기 위해서는 결측치가 많은 데이터를 제거하는 것도 방법이지만 데이터의 양이 data-so-hard.tistory.com 지난 편에서는 fillna() 함수를 통해 평균 수치를 결측치에 삽입하는 것을 진행해봤습니다. 오늘은 좀 더 디테일하게 평균 데이터를 삽입해보려고 하는데요. 우선 판다스호의 데이터를 살펴보겠습니다. 데이터를 보면 성인 컬럼에 man, woman, child 총 3가지의 값이 있는데요. 이럴 경우 단순 평균을 넣을 경우 데이터의 질이 나빠질 수 있습니다. 특히, chil..
 dropna() 파이썬 누락 데이터 제거 [python/seaborn]
dropna() 파이썬 누락 데이터 제거 [python/seaborn]
https://data-so-hard.tistory.com/31 isnull(), notnull() 누락 데이터 확인 [python/seaborn] 엑셀을 가지고 데이터를 다룰 때 가장 불편한 점이 있다면 데이터의 누락과 오류 같은 문제들을 바로 찾기가 쉽지 않다는 점입니다. 이번 시간에는 파이썬을 통해 누락 데이터에 대해 알아보는 data-so-hard.tistory.com 지난 편에서는 파이썬의 간단한 코드를 통해 엑셀에 저장된 데이터 중 누락된 부분을 확인해봤는데요. .이번 시간에는 이 누락된 데이터를 제거하는 방법에 대해 알아보도록 하겠습니다. 우선 지난 시간에 했던 코드를 들고 오겠습니다. import seaborn as sns df= sns.load_dataset('titanic') #누락 데..
 아놀드의 21/22시즌의 기회 창출과 패스 성공률[python/pandas]
아놀드의 21/22시즌의 기회 창출과 패스 성공률[python/pandas]
오늘도 축구 데이터를 가지고 df.plot의 다양한 그래프를 그려보고자 하는데요. 이번에 다뤄볼 데이터는 제가 최근에 입덕한 리버풀의 플레이메이커 트렌트 알렉산더-아놀드의 데이터입니다. 아놀드는 포지션은 오른쪽 풀백이지만 실제 경기를 보고 있으면 공격 전개시 중앙으로 침투하여 중앙 미드필더 같은 모습을 보이거나 우측에서 롱패스와 크로스를 통해 플레이메이커로서 98년생인 어린 나이에도 불구하고 굉장히 좋은 모습을 보여주고 있습니다.그래서 이번에 아놀드의 패스 관련 데이터를 수집해 그래프로 표현봤는데요. 참고한 사이트는 지난 번과 동일하게 fotmob을 통해 수집했습니다. https://www.fotmob.com/ FotMob FotMob is the essential app for matchday. Get..
 손흥민 프리미어리그 시즌별 공격포인트 면적그래프로 나타내보기[python/matplotlib]
손흥민 프리미어리그 시즌별 공격포인트 면적그래프로 나타내보기[python/matplotlib]
안녕하세요, 개발새발입니다. 저는 최근에 일을 하면서 프리미어리그에 흠뻑 빠지게 돼 22/23 시즌을 앞두고 다끝난 21/22시즌을 다시보기 하고 있습니다. 그중에서 득점왕을 차지한 손흥민 선수의 경기를 많이 챙겨보고 있는데요. 이번 시간에는 지난 7년간 프리미어리그에서 활약 중인 손흥민 선수의 공격포인트(득점, 어시스트) 기록은 면적 그래프로 그려보도록 하겠습니다. import pandas as pd import matplotlib.pyplot as plt #한글 처리 from matplotlib import font_manager, rc font_path = "c:/windows/Fonts/malgun.ttf" #한글 폰트 경로 font_name = font_manager.FontProperties(..
 matplotlib 한글 폰트 오류 해결
matplotlib 한글 폰트 오류 해결
import pandas as pd import matplotlib.pyplot as plt df = pd.read_excel('./시도별 전출입 인구수.xlsx', header=0) #빈칸 채워주기 df = df.fillna(method='ffill') #서울에서 다른 지역으로 이동하는 인구수 mask = (df['전출지별'] == '서울특별시') & (df['전입지별'] != '서울특별시') df_seoul = df[mask] df_seoul = df_seoul.drop(['전출지별'], axis=1) #불필요한 전출지별 제게 df_seoul.rename({'전입지별':'전입지'}, axis=1, inplace=True) #컬럼명 변경 df_seoul.set_index('전입지', inplace=Tr..
 matplotlib로 데이터프레임 그래프 그리기 1
matplotlib로 데이터프레임 그래프 그리기 1
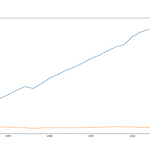
지난 시간에는 df.plot()을 이용해 여러 그래프를 그려봤는데요. 이번 시간에는 또다른 그래프 라이브러리인 maplotlib를 활용해 그래프를 그려보겠습니다. matplotlib는 "파이썬의 표준 시각화 도구"라고 부를 수 있을 정도로 평면 그래프와 관련해 다양한 포맷과 기능을 지원합니다. 또한 객체지향 프로그래밍을 지원해 그래프 요소를 세세하게 꾸밀 수 있는 장점 또한 가지고 있습니다. matplotlib 설명은 여기까지 하고 본격적으로 matplotlib를 이용해 그래프를 그려 보도록하겠습니다. matplotlib를 실행시키기 위해서는 import를 해야 겠죠? 이번에 활용할 데이터프레임은 시도별 전출입 인구수입니다. 코드를 진행해보겠습니다. import pandas as pd import mat..
 df.plot() 데이터프레임 그래프 그리기 - 2
df.plot() 데이터프레임 그래프 그리기 - 2
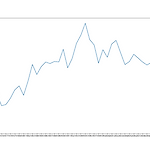
지난 1편에서(데이터프레임 그래프 그리기 - 1 https://data-so-hard.tistory.com/17) 그래프는 완성했지만 시각적으로 명확하게 데이터의 차이를 보여줬다고 볼순 없었는데요. 1편에서의 최종 코드와 그래프를 다시 한번 보겠습니다. import pandas as pd import matplotlib.pyplot as plt df = pd.read_excel('./남북한발전전력량.xlsx', engine='openpyxl') # 데이터프레임 변환 print(df) print('\n') df_ns = df.iloc[[0,5], 3:] # 남북한 연도별 발전전량 합계 추출 df_ns.index = ['South', 'North'] # 행 인덱스 변경 print('\n') print(df_..
 loc와 iloc (3) - 데이터 추가하기
loc와 iloc (3) - 데이터 추가하기
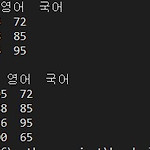
exam_data = {'이름': ['민수', '철수', '광수'], '수학': [80, 90, 100], '영어': [95, 88, 56], '국어' : [72, 85, 95]} df = pd.DataFrame(exam_data) print(df, '\n') 이번에는 데이터 추가하기를 해보겠습니다. 우선 데이터 프레임을 불러오고 추가할 내용을 딕셔너리 형태로 미리 만들어 놓습니다. dj = {"이름":"찰스", "수학":80, "영어":100, "국어":65} df1 = df.append(dj, ignore_index =True) print(df1) 광수 하단에 찰스와 수학,영어,국어 점수가 추가된 것을 확인할 수 있습니다. 데이터 프레임에 새로운 데이터를 추가할 때는 append 함수를 사용하는데요...
 loc와 iloc (2) - 데이터 변경하기
loc와 iloc (2) - 데이터 변경하기
우선 데이터 프레임을 만듭니다. import pandas as pd exam_data = {'이름': ['민수', '철수', '광수'], '수학': [80, 90, 100], '영어': [95, 88, 56], '국어' : [72, 85, 95]} df = pd.DataFrame(exam_data, index= ['A','B','C']) print(df) 우선 지난 1편에서 한 loc와 iloc를 활용해 특정 범위 데이터 표출 예시를 해보겠습니다. 이와 함께 광수와 철수의 영어 점수를 변경해보겠습니다. #iloc로 특정 데이터 보여주기 label1 = df.iloc[0 : 2] print(label1, '\n') #loc로 특정 데이터 보여주기 label2 = df.loc['A' : 'C'] print(..
일을 하는 데 있어 간단한 데이터 프레임 혹은 간단한 자료만 만나면 좋겠지만 현실은 시궁창이죠. 설령 간단한 자료를 만났더라도 이를 가지고 무엇인가 코딩을 짜려면 단순하게 이름만 알아선 힘듭니다. 보통은 특정 컬럼의 어느 위치의 데이터를 가지고 작업을 해야 하는데요. 판다스에서는 이를 'loc' 와 'iloc'로 나눕니다. loc: 인덱스 이름(index label) EX) df.loc['a:c'] -> 'a','b','c' iloc: 정수형 위치 인덱스(integer position) EX) df.iloc[3:7] -> 3,4,5,6 loc는 인덱스의 이름이 있을 때 그 이름을 직접 입력하는 방식입니다. iloc는 인덱스의 정수형 위치를 활용하는 방식입니다. 위의 예시를 보면 알겠지만 범위를 지정할 때..