
목록전체 글 (120)
개발은 처음이라 개발새발
 [selenium] 셀레니움으로 크롤링 해보기 - 네이버 축구 순위 최종장
[selenium] 셀레니움으로 크롤링 해보기 - 네이버 축구 순위 최종장
from selenium import webdriver import pandas as pd #open webdriver chrome_driver = './chromedriver.exe' driver = webdriver.Chrome(chrome_driver) df_bundes_team = pd.DataFrame(columns = ['rank', 'team', 'game', 'win_pt', 'win', 'draw', 'lose', 'gf', 'ga', 'goal_diff']) bundes_football = "https://sports.news.naver.com/wfootball/record/index?category=bundesliga&tab=team" driver.get(bundes_football)..
 [selenium] 셀레니움으로 크롤링 해보기 - 네이버 축구 순위 2편
[selenium] 셀레니움으로 크롤링 해보기 - 네이버 축구 순위 2편
지난 글에서 네이버 분데스리가 팀순위 페이지까지 연동하는 것을 해봤는데요. 코드는 아래와 같습니다. from selenium import webdriver import pandas as pd #open webdriver chrome_driver = './chromedriver.exe' driver = webdriver.Chrome(chrome_driver) df_bundes_team = pd.DataFrame(columns = ['rank', 'team', 'game', 'win_pt', 'win', 'draw', 'lose', 'gf', 'ga', 'goal_diff']) bundes_football = "https://sports.news.naver.com/wfootball/record/index?c..
 [selenium] 셀레니움으로 크롤링 해보기 - 네이버 축구 순위 1편
[selenium] 셀레니움으로 크롤링 해보기 - 네이버 축구 순위 1편
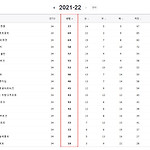
이제 본격적으로 크롤링을 진행해보겠습니다. 우선 전에 적었던 크롬드라이버를 여는 코드까지는 아래와 같습니다. from selenium import webdriver #open webdriver chrome_driver = './chromedriver.exe' driver = webdriver.Chrome(chrome_driver) 제가 이번에 크롤링 해볼 것은 네이버의 해외축구 팀순위 테이블입니다. 그중에서도 저는 분데스리가의 바이에른 뮌헨 팬이라 분데스리가 팀순위를 크롤링 해 이를 데이터 프레임에 저장해 표출해 보도록 하겠습니다. 이를 위해서는 크롤링을 진행하기 전에 컬럼이 들어가 있는 데이터 프레임을 만들어야 하는데요. 우선 네이버 분데스리가 팀순위 테이를 보시죠. 2021/22시즌의 순위 테이블을 ..
 [selenium] 셀레니움으로 크롤링 해보기 - 크롬 드라이버(Chrome driver)
[selenium] 셀레니움으로 크롤링 해보기 - 크롬 드라이버(Chrome driver)
이번에는 크롤링을 해볼까 합니다. 크롤링이라는 단어를 많이 들어봤을테지만 정작 정확한 뜻을 모르는 분도 많을 텐데요. 크롤링이란 간단하게 말하자면 웹페이지에 있는 데이터를 추출해오는 것을 의미합니다. 스포츠 데이터를 예로 들어보면 경기야 얼마든지 볼 수 있지만, 팀과 선수의 기록들을 가지고 재밌게 놀기에는 이와 관련된 회사를 가지 않곤 쉬운 일이 아닌데요. 그러나 크롤링을 할 수 있게 된다면 스포츠 통계 사이트에 있는 데이터를 추출해 저장해서 다양하게 씹고 뜯고 맛보고 즐길 수 있습니다. 그렇다면 지금 바로 크롤링에 대해 알아보도록하겠습니다. 크롤링 라이브러리는 BeautifulSoup4, requests 등 다양하게 있지만 전 selenium을 사용해보려고 합니다. 우선 selenium 라이브러리를 설..
 [반복문/ python3] 2439번 별찍기 - 2
[반복문/ python3] 2439번 별찍기 - 2
2438번에 이어 두번째 별찍기 문제입니다. 2438번과 다른 점이 있다면 별의 위치입니다. 2438번에서는 별의 증가가 오른쪽으로 하나씩 늘어나는 반면 2439번은 역방향으로 왼쪽에서부터 하나씩 늘어나는 걸 확인할 수 있는데요. 방향을 바꾸기 위해서는 "공백"을 활용하면 됩니다. 예를 들어 파이썬에서 3*" "를 할 경우 공백이 3칸 생깁니다. 이때 반드시 큰 따옴표 사이에 한칸을 띄어줘야 공백이 적용됩니다. 코드를 한번 써보겠습니다. N = int(input()) for i in range(1, N+1): #공백 만들기 a = (N-i)*" " #* 곱하기 b = i * "*" ab = a+b print(ab) input 함수에 5를 넣기 때문에 " a= (N-i) * " " "은 " a = (5-i..
 [반복문/ python3] 2438번 별찍기 - 1
[반복문/ python3] 2438번 별찍기 - 1
코딩을 공부할 때는 기본 지식을 쌓기 위해 강의를 들으며 공부하는 것도 좋지만 실질적으로 업무에서 바로 활용하기 위해서는 많은 예제들을 풀어보며 구조를 파악하고 응용하는 능력을 키우는 게 중요합니다. 다양한 예제를 풀어볼 수 있는 백준 알고리즘 사이트를 추천드립니다. 하단 링크를 통해 들어가시면 반복문, 조건문 등 다양한 예제를 풀어보실 수 있습니다. https://www.acmicpc.net/step 단계별로 풀어보기 단계별은 @jh05013님이 관리하고 계십니다. 단계제목설명정보총 문제내가 맞은 문제1입출력과 사칙연산입력, 출력과 사칙연산을 연습해 봅시다. Hello World!132조건문if 등의 조건문을 사용해 봅시다 www.acmicpc.net 이번 시간에는 반복문 2438번 별찍기-1 예제를 ..
 loc와 iloc (3) - 데이터 추가하기
loc와 iloc (3) - 데이터 추가하기
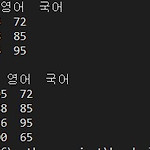
exam_data = {'이름': ['민수', '철수', '광수'], '수학': [80, 90, 100], '영어': [95, 88, 56], '국어' : [72, 85, 95]} df = pd.DataFrame(exam_data) print(df, '\n') 이번에는 데이터 추가하기를 해보겠습니다. 우선 데이터 프레임을 불러오고 추가할 내용을 딕셔너리 형태로 미리 만들어 놓습니다. dj = {"이름":"찰스", "수학":80, "영어":100, "국어":65} df1 = df.append(dj, ignore_index =True) print(df1) 광수 하단에 찰스와 수학,영어,국어 점수가 추가된 것을 확인할 수 있습니다. 데이터 프레임에 새로운 데이터를 추가할 때는 append 함수를 사용하는데요...
 loc와 iloc (2) - 데이터 변경하기
loc와 iloc (2) - 데이터 변경하기
우선 데이터 프레임을 만듭니다. import pandas as pd exam_data = {'이름': ['민수', '철수', '광수'], '수학': [80, 90, 100], '영어': [95, 88, 56], '국어' : [72, 85, 95]} df = pd.DataFrame(exam_data, index= ['A','B','C']) print(df) 우선 지난 1편에서 한 loc와 iloc를 활용해 특정 범위 데이터 표출 예시를 해보겠습니다. 이와 함께 광수와 철수의 영어 점수를 변경해보겠습니다. #iloc로 특정 데이터 보여주기 label1 = df.iloc[0 : 2] print(label1, '\n') #loc로 특정 데이터 보여주기 label2 = df.loc['A' : 'C'] print(..
일을 하는 데 있어 간단한 데이터 프레임 혹은 간단한 자료만 만나면 좋겠지만 현실은 시궁창이죠. 설령 간단한 자료를 만났더라도 이를 가지고 무엇인가 코딩을 짜려면 단순하게 이름만 알아선 힘듭니다. 보통은 특정 컬럼의 어느 위치의 데이터를 가지고 작업을 해야 하는데요. 판다스에서는 이를 'loc' 와 'iloc'로 나눕니다. loc: 인덱스 이름(index label) EX) df.loc['a:c'] -> 'a','b','c' iloc: 정수형 위치 인덱스(integer position) EX) df.iloc[3:7] -> 3,4,5,6 loc는 인덱스의 이름이 있을 때 그 이름을 직접 입력하는 방식입니다. iloc는 인덱스의 정수형 위치를 활용하는 방식입니다. 위의 예시를 보면 알겠지만 범위를 지정할 때..
 agg 함수를 이용한 여러 스탯 평균 구하기
agg 함수를 이용한 여러 스탯 평균 구하기
스포츠 데이터를 다루는 직업을 하면서 게임에 적용할 새로운 가공 데이터를 생성하거나 게임 페이지에 표출할 데이터를 만들어야 할 때 항상 패시브로 들어가는 데이터가 있다면 '평균'입니다. 분량이 많지 않다면 엑셀로 간다하게 할수도 있지만 한 선수의 시즌 전체, 더 나아가 해당 시즌에 출전한 모든 선수의 평균을 구해야 한다고 하면 개인 역량상 엑셀 함수만으로 꽤나 막막합니다. 이때 간단한 판다스 코드가 있다면 "groupby(['column']).agg({key: value})" 입니다. 우선 데이터를 불러옵니다. 전 개인적으로 크롤링한 kbl 21/22 정규시즌을 불러오겠습니다. import pandas as pd import numpy as np df = pd.read_excel("kbl.xlsx", s..